
OpenAIのGPTBot:WebクローリングでAIモデルを強化!
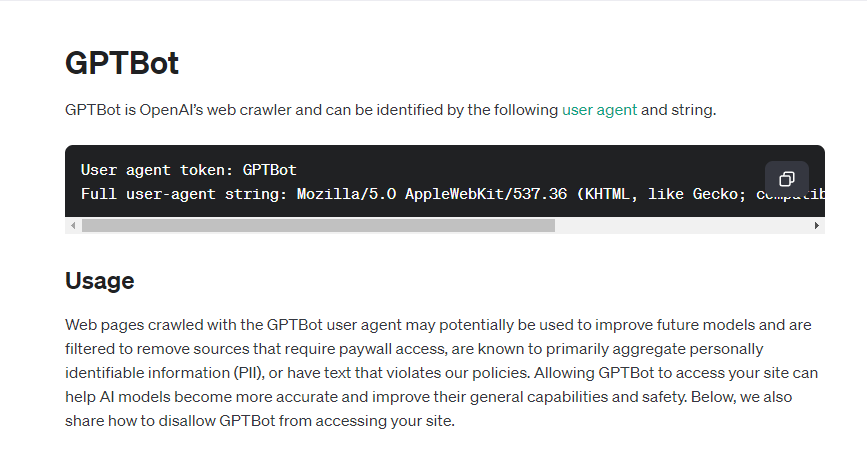
OpenAIが「GPTBot」というWebクローリングツールを導入しました。これは、将来のGPTモデルの能力を向上させることを目的としています。
OpenAIは、GPTBotを通じて収集されたデータがモデルの精度向上と機能拡張に寄与する可能性があると述べ、これはAIパワードの言語モデルの進化における重要なステップです。
Webクローラー、またはWebスパイダーとも呼ばれるものは、広大なインターネット上のコンテンツをインデックス化する重要な役割を果たしています。GoogleやBingなどの有名な検索エンジンは、これらのボットを使用して関連するウェブページで検索結果を埋めています。
OpenAIのGPTBotには明確な目的があります。それは、ペイウォール、個人データの収集、またはOpenAIのポリシーに違反するコンテンツと関わらず、公に利用可能なデータを収集することです。
ウェブサイトの所有者は、標準のサーバーファイル内に「disallow」コマンドを実装することで、GPTBotがサイトをクロールするのを防ぐことができます。これにより、コンテンツのどの部分がウェブクローラーにアクセス可能かを制御できます。
OpenAIの発表は、同社が現行のGPT-4モデルを後継すると予想されている「GPT-5」の商標出願に続いています。
この出願は、2022年7月18日にアメリカ特許商標庁に提出され、AIベースの人間の音声とテキスト、音声からテキストへの変換、音声認識、音声合成における「GPT-5」の使用を包括しています。
ただし、GPT-5商標出願についてはAI愛好家の間で興奮が広がっていますが、OpenAIのCEOであるSam Altmanは早急な期待に対して警告しました。Altmanは、GPT-5のトレーニングを開始する前に、広範な安全性監査が実施される必要があるため、会社はまだそのプロセスを始める段階には遠いと明かしました。
OpenAIの最近の取り組みは論議を呼んでいます。特に著作権と同意の問題に関連して、同社のデータ収集プラクティスについて懸念が生じています。
今年6月、日本のプライバシー規制当局はOpenAIに対して未承認のデータ収集について警告を発しました。また、イタリアは欧州連合のプライバシー法に違反したとして、ChatGPTの使用を一時的に禁止しました。
OpenAIとMicrosoftは、現在、ChatGPTユーザーの相互作用からの個人情報が適切な同意なしにアクセスされたと主張する16人の原告による集団訴訟に直面しています。また、GitHub Copilotに関する訴訟もあり、原告はこのコード生成ツールが開発者のコードを適切な帰属情報を提供せずにスクレイピングしたと主張しています。
これらの主張が真実である場合、OpenAIとMicrosoftはWebスクレイピングのケースに関連する法的前例である「コンピュータ詐欺および悪用防止法」に違反する可能性があります。
OpenAIはAI技術の限界を押し広げ続ける一方で、AIの分野での責任ある倫理的な開発を確保するためにこれらの課題に立ち向かわなければなりません。
出典:GPTBot





